SQL学习笔记
——————————————————————————————————————————————— V2.0 2021.05
1 SQL基础语法
1 | |
SQL的学习方法:分步解题,多练,学会逐步生成中间表格(同时也要锻炼无数据库情况下查错能力),积累用法和思路,套用
1.1 describe
1 | |
查看数据字典,表格有哪些【字段】【字段的数据类型】【注释】
| 架构 | 说明 |
|---|---|
| ods(Operational Data Store):操作型数据仓库 | 同步业务生产过程中的所有数据,比edw更加详细,冗余和复杂度也更高 |
| edw(Enterprise Data Warehouse):企业数据库 | 已处理完成并进行过汇总的,可供业务直接使用的企业数据库 |
| edw_s:安全级别更高的企业数据库 | 存储安全级别较高的敏感或机密数据,例如用户的身份证号、手机号、真实姓名 |
| ddm(Distributed Database Middleware):局部数据库 | 专门针对某个具体的应用或需求建设的局部数据库,只关心自己需要的数据。不会全盘考虑企业整体的数据架构和应用,每个应用都有自己的DM。所以DM可以基于仓库建设也可以独立建设。 |

1.2 select
1 | |
select原理是先创建表头,最后生成表,可以理解为执行两次(因为后面group by,order by 1,2,3)
–查看数据样式,此时的 limit 不需要和 order by 连用,减少消耗的缓存资源
1.3 from
从数据库中找到from后指定的表格,复制一张完全一样的表格用于后续的处理和查询
1.4 where
基于from复制的表格,按照where后的条件对表格中的行进行筛选
| 用法 | 备注 |
|---|---|
| = | 单个数值精确匹配 |
| between A and B | 匹配包含AB及AB之间的所有值 |
| in(A,B,C,D) | 可以实现多选,not in可以反选 |
| and/or | 可以并列多个条件(and用于不同字段,or用于同一字段 |
| like | 配合通配符进行模糊匹配(’%’代表任意数量字符,”_”只代表单个字符) |
1.5 group by
对数据进行分组 = 对group by后的字段进行去重合并,并作为后续聚合运算的依据
group by其实只指定了聚合函数的计算依据,具体的聚合运算还是要由聚合函数进行
==== group by 重点:
因为group by先运行,并且运行后,表格中的非聚合字段已经形成了,所以select后的非聚合字段一定要与group by后指定的字段一致
也就是说:group by后没有的非聚合字段select无法显示,但group by后有的非聚合字段select可以选择不显示
因为,select会运行两次
第一次最先运行:按照字段原始名称和别名新建表头
第二次最后运行:基于from、join、where、group by、having处理好的数据表格,按照select后的计算规则,计算并在表头后显示字段对应的数值
所以group by可以使用1,2等数字直接引用select后的字段名称,直接用于去重合并
1.6 having
由于SQL的单向执行的,而where已经在group by之前执行过了,如果要在group by后再对局和预算的结果进行筛选,需要使用新语句having
并且,having是在分组(去重合并)后运行的,因此having只可以对
作为分组依据的非聚合字段
任意分组后聚合运算的结果
进行筛选,除了对象,having具体的语法和where完全一致
1.7 order by
按照字段的顺序对表格的行进行排序,默认升序,字段后加DESC为降序
order by在select前运行,因此可以依据select后没有,但表格中有的字段进行排序
1.8 limit
1 | |
- 查看数据也可用top
1 | |
limit 和 order by 连用
按照order by排序后的表格,限制最终显示表格的行数,常用来取固定名次的数据
应用:超大分页查询
1 | |
SQL并不是跳过offset行,而是取offset+N行,然后返回放弃前offset行,返回N行,当offset特别大的时候,效率就非常低下
1 | |
1.9 聚合函数
聚合函数也可以不和group by一起用,这样就可以求整个表格的数值
1 | |
| 函数 | 备注 |
|---|---|
| sum() | 返回总和 |
| count() | 返回行数 |
| avg() | 返回平均值 |
| max() | 返回最大值 |
| min() | 返回最小值 |
count(*)可以快速查看表格有多少行,又不占用太多资源
1.10 distinct
distinct只能在select后,第一个筛选字段前,可以
1 | |
同时对两个字段去重,同Excel会删除两个字段都重复的,类似于筛选’A+B’
1 | |
可以用group by实现多个字段去重合并,作用同distinct
1.11 执行顺序
1 | |
1 | |
order by之前称为准备表格
order by之后为查询字段
在阅读SQL代码和书写时,可以先从from和join语句看起,明确用了哪些表,然后看select查询和创建了哪些字段,接下来细致研究代码细节,最后看where的筛选逻辑
1.12 别名
咨询别名规则
表和变量名中不要出现空格,可使用下划线 ‘_’
函数名不能用于别名,如窗口函数别名不能用 ‘rank’
在各个库中,表和字段别名尽量统一,方便代码移植,减少使用a,b来别名,别名要有含义
2 SQL进阶
2.1 表连接
2.1.1 join
left join :左连接,返回左表中所有的记录以及右表中连接字段相等的记录。
right join :右连接,返回右表中所有的记录以及左表中连接字段相等的记录。
(join) inner join: 内连接,又叫等值连接,只返回两个表中连接字段相等的行。
full join:外连接,返回两个表中的行:left join + right join。
- mysql不支持完全外部连接,需要union两个左右连接
cross join:结果是笛卡尔积,就是第一个表的行数乘以第二个表的行数。
关键字: on
数据库在通过连接两张或多张表来返回记录时,都会生成一张中间的临时表,然后再将这张临时表返回给用户。
表面上,join是各种逻辑的表连接,实际上,join是一种运算逻辑(算法)
- 遍历匹配,向下增添(不同于vlookup,vlookup只匹配第一个)
- 左右连接就是保留数据
假设有两张表:
表1: tab1
| name | id |
|---|---|
| AAA | 1 |
| BBB | 2 |
| CCC | 3 |
| CCC | 4 |
表2: tab2
| name | size |
|---|---|
| BBB | 10 |
| CCC | 20 |
| BBB | 30 |
| DDD | 40 |
中间表 on条件:tab1.name = tab2.name
| tab1.name | tab1.id | tab2.name | tab2.size |
|---|---|---|---|
| AAA | 1 | null | null |
| BBB | 2 | BBB | 10 |
| BBB | 2 | BBB | 30 |
| CCC | 3 | CCC | 20 |
| CCC | 4 | CCC | 20 |
| null | null | DDD | 40 |
举例左连接left join结果(只保留左侧连接建不为空的行),注意两个连接键都会保留,故不能同名
1 | |
| tab1.name | tab1.id | tab2.name | tab2.size |
|---|---|---|---|
| AAA | 1 | null | null |
| BBB | 2 | BBB | 10 |
| BBB | 2 | BBB | 30 |
| CCC | 3 | CCC | 20 |
| CCC | 4 | CCC | 20 |
on后面的筛选条件和where的筛选条件有什么不同?
on比where运行得早,数据库会根据on的条件对数据进行筛选再进行连接
而where则是连接完成后,再进行筛选
1 | |
| tab1.name | tab1.id | tab2.name | tab2.size |
|---|---|---|---|
| AAA | 1 | null | null |
| BBB | 2 | BBB | 30 |
| CCC | 3 | null | null |
| CCC | 4 | null | null |
2.1.2 union
union 和 union all 的区别
| 区别 | union | union all |
|---|---|---|
| 对重复结果的处理不同 | 取唯一值,记录没有重复(union在进行表链接后会筛选掉重复的记录) | 直接连接,取到得是所有值,记录可能有重复 |
| 对排序的处理不同 | 按照字段的顺序进行排序 | 简单的将两个结果合并后就返回 |
从效率上说,union all 要比union快很多,所以,如果可以确认合并的两个结果集中不包含重复数据且不需要排序时的话,那么就使用union all。
1 | |
注意
1、union 和 union all都可以将多个结果集合并,而不仅仅是两个,所以可将多个结果集串起来。
2、使用union和union all必须保证各个select 集合的结果有相同个数的列,并且每个列的类型是一样的。但列名则不一定需要相同,oracle会将第一个结果的列名作为结果集的列名。
2.1.3 whit as
SQL可读性增强。比如对于特定with子查询取个有意义的名字等。
with子查询只执行一次,将结果存储在用户临时表空间中,可以引用多次,增强性能。
1 | |
2.2 窗口函数
表面上,窗口函数是基于某个排序规则进行排序并计算
实际上,窗口函数是对准备好的表格,在任意分组内部进行排序和计算(为了区分,我们称之为分区)(也就是指定任意详细级别进行各种自定义的运算)
- from–where之后,再创建一个之前准备好的表格(还未排序和限制)
- 根据partition by 后的字段(没有则默认针对整个表)形成的分区(不去重合并)
- 在分区内根据order by后的条件对所有行进行排序
- 注意:mysql支持在over中使用聚合字段 - ```mysql row_number() over(partition by 门店名称 order by sum(gmv)) r
2
3
4
5
6
7
8
9
10
11
12
13
14
15
164. 计算over()前函数的结果
#### 2.2.1 row_number/dense_rank/rank
根据排序分配序号
| 函数名 | 备注 | 举例 |
| ------------ | -------------------------------------------- | --------- |
| row_number() | 根据分区内的排序,分配唯一且连续排名序号 | 1,2,3,4,5 |
| dense_rank() | 根据分区内的排序,分配不唯一且连续排名序号 | 1,1,2,2,3 |
| rank() | 根据分区内的排序,分配不唯一且不连续排名序号 | 1,1,3,3,5 |
如果是时间排序,注意确定好详细级别
```mysql
,row_number() over(partition by 门店名称,平台 order by 日期) r
1 | |
1 | |
2.2.2 first_value/nth_value
根据排序取具体字段数值
| 函数名 | 备注 |
|---|---|
| first_value(字段) | 根据分区内的排序,返回排在第一行的对应的字段数值(降序就可以去最后一行对应的数值) |
| nth_value(字段,n) | 返回分区内的排序第n行的字段数值。如果第n行还未运行到,则返回 |
1 | |
1 | |
1 | |

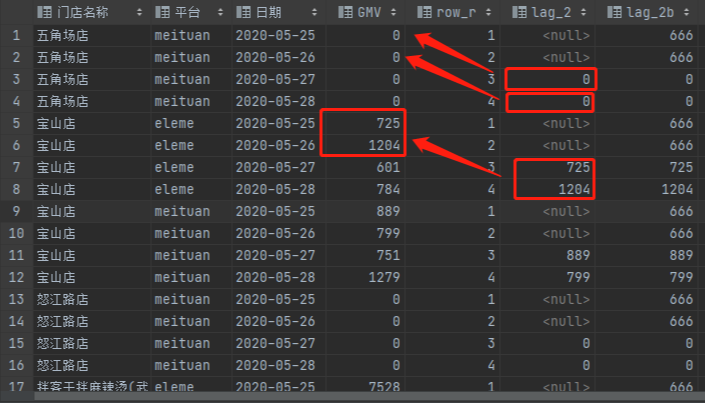
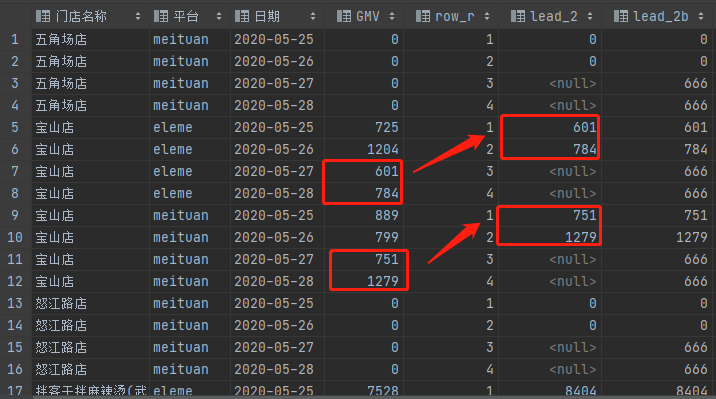
2.2.3 lag/lead
根据排序取上下几行的数值
| 函数名 | 备注 |
|---|---|
| lag(字段,n,默认值) | 返回分区内,本行前n行的字段数值,如果为空则填充默认值 |
| lead(字段,n,默认值) | 返回分区内,本行后n行的字段数值,如果为空则填充默认值 |
1 | |
1 | |

1 | |
1 | |
2.2.4 percent_rank/cume_dist
根据排序统计分布位置
| 函数名 | 备注 | 取值 |
|---|---|---|
| percent_rank() | 根据分区内的排序,从0开始统计当前行所在排序中的处于百分之多少的位置(不管指定值与分组序列中某值是否重复,均将此值视为序列一部分) | 0<= percent_rank() <=1 |
| cume_dist() | 根据分区内的排序,从0之后开始统计当前行所在排序中的百分比分布位置(如果指定值与分组序列中某值重复,则将二值视为一个值处理) | 0< cume_dist() <=1 |
1 | |
1 | |

cume_dist的计算方法:小于等于当前行值的行数/总行数。
比如,第3行值为10,有3行的值小于等于10,总行数10行,因此CUME_DIST为3/10=0.3 。
再比如,第4行值为40,行值小于等于40的共5行,总行数10行,因此CUME_DIST为5/10=0.5
PERCENT_RANK的计算方法:当前RANK值-1/总行数-1 。
比如,第4行的RANK值为4,总行数10行,因此PERCENT_RANK为4-1/10-1= 0.333333333333333。
再比如,第7行的RANK值为6,总行数10行,因此PERCENT_RANK为6-1/10-1=0.555555555555556。
2.2.5 ntile
在排序内分组
| 函数名 | 备注 |
|---|---|
| ntile(n) | 将排序内的行分为n组,根据分区内的排序,返回每一行是第几组 |
1 | |
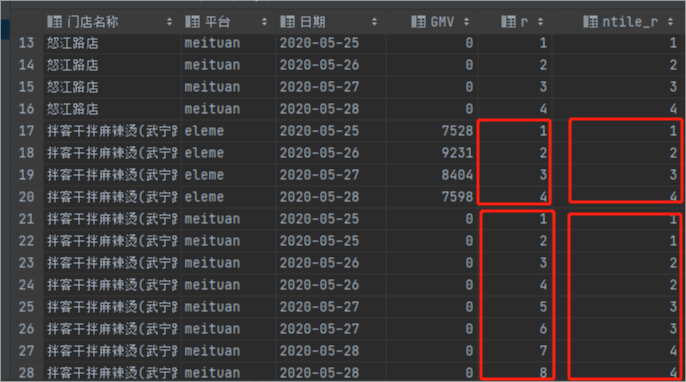
无论最终查询出的表格排序如何,窗口函数计算的列都只根窗口函数指定排序下的计算结果一致
2.2.6 取四分位各函数效率及准确率比较
1 | |

总数54,计算四分位应该在13,以上方法中最快的是cume_dist(percent_rank和row_number都需要再绕一步)
2.2.7 各种聚合运算都支持
1 | |
- over()中分为partition by子句、order by子句和window子句
- 只使用partition by子句,未指定order by,聚合为分组内的聚合
- 使用partition by和order by子句,未使用window子句的情况下,默认从起点到当前行
1 | |
2.2.8 窗口子句(window子句)
preceding:往前
following:往后
current row:当前行
unbounded:起点
unbounded preceding 表示从前面的起点
unbounded following 表示到后面的终点
1 | |

3 特殊函数用法
3.1 数值处理函数
3.1.1 round
round(数值型字段,n):对数值型字段取小数点后n位小数
1 | |
1 | |
3.1.2 abs
abs(数值型字段):取数值型字段的绝对值
1 | |
3.1.3 coalesce
coalesce(字段,数值):将字段中的null填充为默认数值
1 | |
3.1.4 isnull
1 | |
3.1.5 ifnull
1 | |
3.1.6 nullif
1 | |
3.2 数据类型转化
3.2.1 cast
cast(字段 as 要转换成的数据类型)
1 | |
3.3 字符处理函数
3.3.1 substring
1 | |
3.3.2 left
1 | |
3.3.3 concat
- 连接括号内任意的字符串
- 也可以直接处理时间类型的数据,因为时间类型的数据本质就是字符串
1 | |
3.3.4 replace
1 | |
3.3.5 ucase
1 | |
3.3.6 lcase
1 | |
3.3.7 len()
len()返回某个文本字段的长度
3.3.8 position()
1 | |
3.4 时间函数
3.4.1 date_format
date_format() - 格式化某个字段的显示方式
1 | |
MySQL时间数据的默认格式
| 名称 | 格式 |
|---|---|
| DATE | YYYY-MM-DD |
| DATETIME | YYYY-MM-DD HH:MM:SS |
| TIMESTAMP | YYYY-MM-DD HH:MM:SS |
| YEAR | YYYY 或 YY |
1 | |
3.4.2 date_add
date_add() 在日期中添加或减去指定的时间间隔(时间偏移)
date_add(date,interval n 时间单位)在日期往后偏移n个时间单位(可以为负数)
1 | |
date_sub(date,interval n 时间单位)在日期往前偏移n个时间单位(可以为负数)
| 时间单位 | 时间单位 |
|---|---|
| MICROSECOND | |
| SECOND | SECOND_MICROSECOND |
| MINUTE | MINUTE_MICROSECOND,MINUTE_SECOND |
| HOUR | HOUR_MICROSECOND,HOUR_SECOND,HOUR_MINUTE, |
| DAY | DAY_MICROSECOND,DAY_SECOND,DAY_MINUTE,DAY_HOUR |
| WEEK | |
| MONTH | |
| QUARTER | |
| YEAR | YEAR_MONTH |
3.4.3 datediff
datediff(date1,date2)函数返回两个日期之间的天数。(注意date1 > date2,结果为正)
1 | |
3.4.4 timestampdiff
timestampdiff(时间单位,开始时间,结束时间) 返回结束时间和开始时间之间有多少个时间单位。(注意date1 < date2,结果为正)
1 | |
3.5 逻辑函数
3.5.1 if
1 | |
1 | |
3.5.2 case when
1 | |
逻辑函数的经典用法
数值替换
条件计算
任意多选
行列转置
4 报错汇总
4.1 group by 报错

1 | |
select 选取分组中的列+聚合函数 from 表名称 group by 分组的列
从语法格式来看,是先有分组,再确定检索的列,检索的列只能在参加分组的列中选。
再看一下only_full_group_by的意思是:对于 group by聚合操作,如果在select 中的列,没有在 group by中出现,那么这个SQL是不合法的,因为列不在 group by从句中,也就是说查出来的列必须在group by后面出现否则就会报错,或者这个字段出现在聚合函数里面。
解决:group by 后面补上缺失的非聚合字段
4.2 from子查询 别名报错

1 | |
from子查询必须要有别名
4.3 where聚合函数的无效用法

1 | |
“聚合函数的无效用法”
1 | |
4.4 join表后字段名重复

1 | |
解决:通常同名是连接键,把其中一张表的同名字段别名或者带上表名称
5 代码规范
第一版:
- 多写注释
- 逗号写在字段前面
- 注意换行
- 每行尽量以核心语句开头
- 核心语句后的内容能写在一行尽量写在一行
- where条件过长时,每个都要换行
- 注意缩进
- case when 同一级别的条件
- 子查询,子查询可以换行缩进,也可以直接在代码后缩进
- 别名尽量统一缩进
- 代码结束处加 ‘;’
第二版:
查询核心语句顺序
1 | |
一、短代码-仅含 select 和 from,且 select 后字段不超过3个
- 短代码不换行,直接写成一行
二、长代码
01. 核心语句换行,join 连接表换行,on 连接键换行,多连接键也换行
02. where/having 多条件 and/or 换行,单条件语句不换行,例如:between and、sif.branch in (‘上海分行’,’北京分行’)
03. group by 后字段不换行,order by 后字段不换行
04. 括号内不加空格,函数的括号前不加空格,括号内不加空格,例如:(‘上海分行’,’北京分行’)、sum(amount)
05. 运算符前后加空格:= 、>=、<=、>、<、!=、-、+
06. 含乘除的运算符前后不加空格:、/、%
07. select 后只有一个字段不换行,select 后的*算作一个字段来看
08. distinct 不换行
09. 子查询缩进-select后子查询,括号换行,子查询缩进在括号后,括号上下对齐
10. 子查询缩进-from后子查询,括号换行,括号与from同一缩进,括号中的查询缩进在括号后
11. 子查询缩进-from后两个子查询连接,join前后空行,保证两个被连接的子查询与 from 和 join 在同一缩进,括号上下对齐
12. 子查询缩进-where后子查询,括号不换行,括号在in/运算符 后,子查询缩进在括号后,括号上下对齐
13. union前后为完整查询语句,且需要前后空行,完整查询语句不需要括号
14. 窗口函数不换行
15. 函数嵌套,函数除了 case when 其余函数和函数的多重嵌套都写一行
16. case when 函数,仅有一对when和then时,全部写一行
17. case when 函数,when 后仅一个条件时,when 和 then 在同一行,若 when 后有多个条件时 then 换行,且前后的 then 都换行,保持代码块内格式统一
18. case when 函数,else 和 end 在同一行,case when 函数在本身有换行时,外面嵌套的函数,后半个括号要换行与前半个括号上下对齐
19. case when 函数嵌套,then 换行与 when 对齐
20. with as 中间表,表名换行,括号换行,代码缩进在括号后,多个中间表时加空行区分
6 其他
6.1 Datagrip 数据导出
右键导出csv或xlsx数据表用于熟悉数据字段,不懂或不清晰的一定要向同事或数仓请教
mysql导出csv乱码,是csv文件本身的文本编码问题导致的
- 鼠标右键点击选中的 csv 文件,在弹出的菜单中选择“编辑”,则系统会用文本方式(记事本)打开该 csv 文件;
- 打开 csv 文件后,进行“另存为”操作,在弹出的界面底部位置有“编码”,修改编码方式即可: 从UTF-8改成 ANSI 。保存;
- 再用 excel 打开后,显示汉字正常。
6.2 excel导入本地mysql
SQLyog
- 创建数据库
- 导入外部数据库(开始新工作)
- excel(csv注意格式)–> 选择文件
- 从数据源拷贝
- 选择sheet
Datagrip
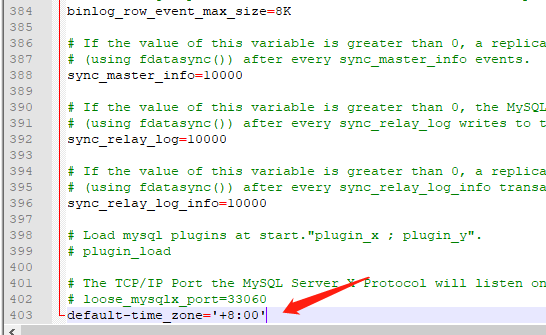
本地数据时区问题说明
Server returns invalid timezone. Go to ‘Advanced’ tab and set ‘serverTimezone’ property manually
https://www.cnblogs.com/qingjiawen/p/14200327.html
1 | |
我的安装目录在
1 | |
在my.ini文件最后一行输入
1 | |
7 场景用法总结
7.1 自身使用习惯问题小结
group by 后多使用having而不是套子查询用where,节省代码复杂度。
熟悉窗口函数使用,窗口函数可直接调用聚合函数。
count和sum的使用区别,同时注意聚合函数要考虑好 group by 的使用。
有些情况表连接效率高(可使用表自连接),有些情况多重子查询效率高。
使用 with as 用法优化代码。
练习计算同比环比
7.2 实用代码
只举例部分:
1 | |
1 | |
1 | |
1 | |
1 | |
1 | |
1 | |
8 刷题
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!